gipsy_danger::ConcurrentRBTree. On an Intel i9-13900K, it delivers 1.52× aggregate throughput and up to 1.55× read throughput over folly::ConcurrentSkipList on 16-thread, 8-million-entry read-heavy workloads. The API is a drop-in replacement. The trick isn’t a new algorithm — it’s a dual-indexed layout that keeps reads fully lock-free while letting the tree itself stay dead-simple inside a single-writer critical section. This post explains how, why it actually wins on real silicon (hint: it’s not the cache hit rate), and where it loses.
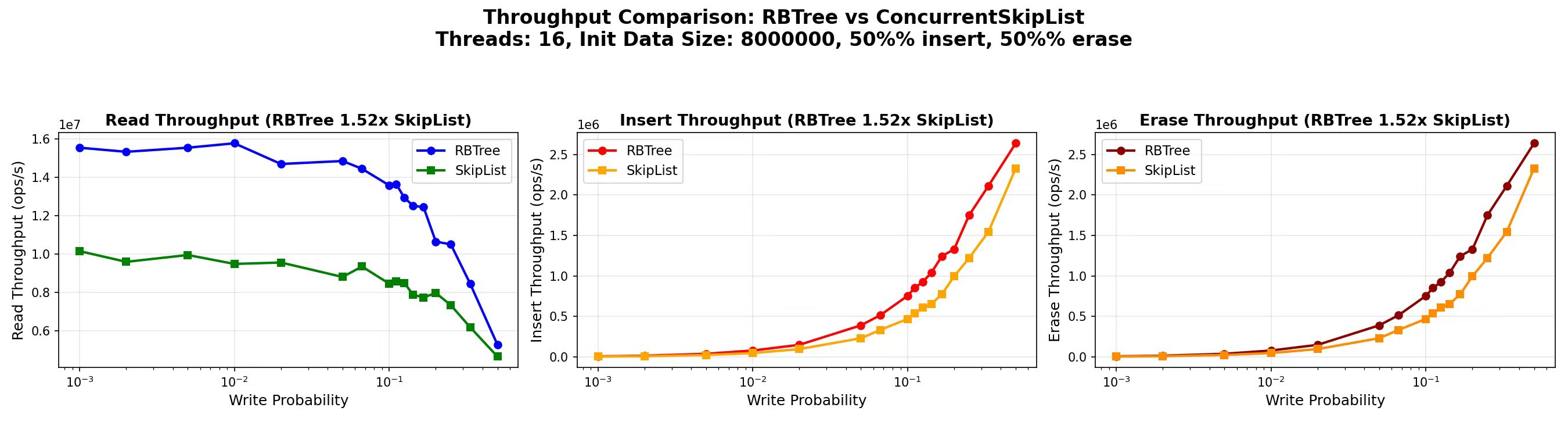
16 threads · 8M int32_t entries · Intel i9-13900K
The question I was trying to answer
folly::ConcurrentSkipList is the de-facto C++ concurrent ordered set. It scales writes beautifully via CAS-based splicing and has been battle-tested inside Meta for years. For most workloads, it is the right answer.
But the workloads I care about — in-memory caches, real-time indexes, feature stores — share one property: reads dominate, usually more than 90% of all operations. And on those workloads, I had a nagging suspicion that a skip list’s constant factor was leaving performance on the table.
Skip lists are probabilistically balanced. A lookup on an N-entry skip list touches roughly 1.44 × log₂(N) forward pointers — each potentially on a distinct cache line. A red-black tree lookup touches log₂(N) child pointers, and the top few tree levels stay hot in L1 across all threads. The Big-O is identical. The constants should not be.
So I asked: can a concurrent red-black tree compete with folly::ConcurrentSkipList, given all the hand-over-hand locking nightmares that usually come with tree-based concurrency?
Turns out: yes — if you are willing to make one specific trade-off.
The key insight: the tree is a hint, the list is the truth
The traditional problem with concurrent balanced trees is that rotations perturb search paths. A reader mid-descent can land on a subtree that just rotated away from under it — and now it is looking at a node whose subtree contains the wrong keys. Classical solutions (Bronson et al.’s relaxed-AVL, hand-over-hand locking, optimistic versioning) all try to make the tree itself tolerate concurrent writes.
I went the other way.
The tree in ConcurrentRBTree is an approximate index, not the source of truth. Alongside it, I maintain a sorted singly-linked list threaded through all data nodes in key order, with acquire/release semantics on the next_ pointers. Both structures point at the same underlying nodes:


Two indexes, one set of nodes: every blue box in the list and every colored circle in the tree is the same physical Node* in memory.
Why this works: rotations do not change sorted order. If a reader’s tree descent lands on a predecessor that is close to the right position but off by a few slots (because a rotation just happened), walking the linked list forward from that predecessor will still find the correct target in O(1) expected steps.
Reads therefore proceed like this:
- Descend the tree with relaxed-atomic loads to find an approximate
less_bound. - Walk the linked list forward up to 3 steps looking for the exact target.
- If 3 steps is not enough, assume rotation interference and retry from the root.
No locks on the read path. Ever.
The write path: serialize only the commit
Writers also use the tree as a hint. Every writer thread independently descends the tree lock-free, finding an estimated_less_bound. Only then does it acquire a single cache-line-aligned std::atomic_flag spinlock. Inside the critical section, it:
- Refines the bound by walking the linked list (same 3-step check as readers).
- If the walk fails, releases the lock and retries from the top.
- Otherwise: splices the new node into the linked list (acquire/release
next_), attaches or detaches it in the tree (relaxed stores — we are the only writer), performs rebalancing, and finally toggles the node’saccessible_flag (acquire/release) to make it visible to readers.
while (true) {
auto estimated = findEstimatedLessBoundForWrite(value); // lock-free descent
while (write_leader_flag_.test_and_set(std::memory_order_acquire))
std::this_thread::yield();
auto exact = findExactLessBoundForWrite(estimated, value); // validate via list
if (exact == nullptr) { status = RETRY; }
else { internalInsert(new_node, exact); status = SUCCESS; }
write_leader_flag_.clear(std::memory_order_release);
if (status != RETRY) return;
}
The structural mutation is serialized across writers. This is the trade-off. I gave up fine-grained write concurrency in exchange for:
- A tree that never needs per-node locks.
- A commit section that runs in tens of cycles — short enough to not matter in read-heavy workloads.
- Implementation simplicity: the whole library is ~1000 lines of C++17 in a single header.
Because only one writer ever mutates the tree at a time, every child-pointer store inside the critical section uses memory_order_relaxed. Acquire/release fencing is needed on exactly two edges: the next_ pointer of the sorted list, and the per-node accessible_ flag — the two things readers actually follow.
Why it’s actually faster (and it’s not what you’d guess)
Here is what surprised me the first time I ran perf stat. Workload: 10% writes, 16 threads, 8M entries.
| Metric | ConcurrentRBTree | ConcurrentSkipList |
|---|---|---|
| Data references | 8.08 × 10⁹ | 15.19 × 10⁹ |
| Instructions | 22.0 × 10⁹ | 42.0 × 10⁹ |
| Branches | 4.41 × 10⁹ | 8.74 × 10⁹ |
| L1d miss rate | 11.0% | 9.2% |
| LLd miss rate | 4.1% | 2.4% |
| Branch mispredict rate | 13.1% | 9.1% |
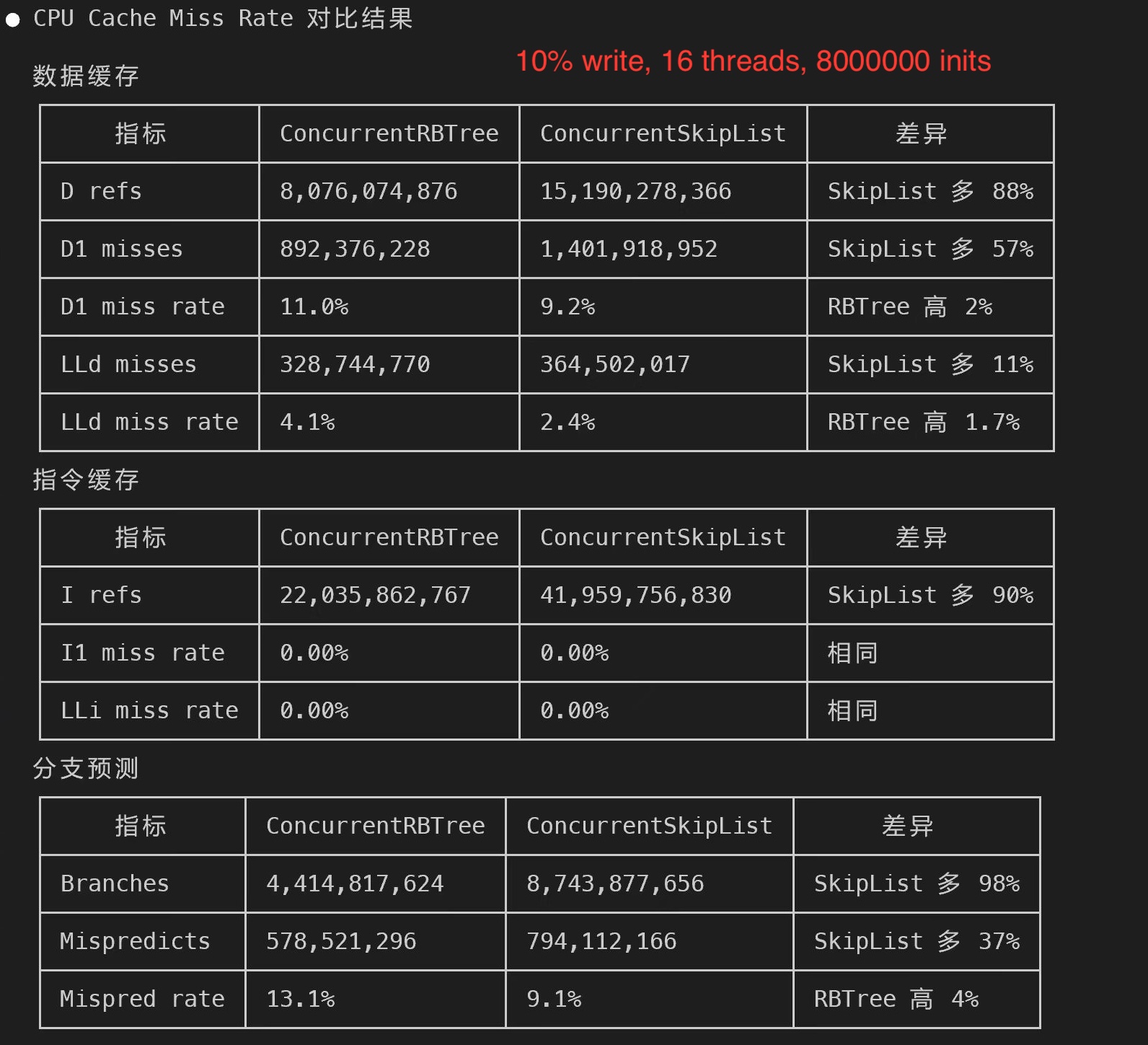
Read the last three rows twice. The skip list has better cache hit rates and better branch prediction than my tree. Its nodes are smaller, its pointer-chase pattern is more predictable.
And yet — the tree wins by 1.5×. How?
Look at the first three rows. The tree does roughly half as many data references, half as many instructions, and half as many branches per operation. Even with a worse per-access miss rate, the absolute number of L1d misses is lower (892M vs. 1.40B), because there are far fewer accesses in total. The same holds for absolute branch mispredicts (578M vs. 794M).
The mental model I landed on: a red-black tree operation is more expensive per step, but does half as many steps. A skip list operation is cheaper per step, but does twice as many. In read-heavy regimes, the second effect dominates. Flip the workload to write-heavy with a tight working set and the story reverses.
This is, retroactively, the boring explanation from any data-structures textbook: both structures are O(log n), but constant factors matter, and the red-black tree’s constant is about 1/2 that of the skip list. I just had not seen it measured cleanly in a concurrent C++ setting before.
Where it loses (and you should care)
Every benchmark post over-claims. I want to be honest about this.
1. Heavy writes on tiny working sets. At 27 threads and 100K entries (comfortably L2-resident) with write probability 0.5, ConcurrentRBTree runs at 0.73× of ConcurrentSkipList’s throughput. The single writer-side spinlock serializes all mutations, and on workloads where the lock-free descent is short, the critical section dominates total time. folly::ConcurrentSkipList’s CAS-based writer scales linearly here.
2. Memory overhead. Each tree node carries a parent pointer, two child pointers, a next_ pointer, a color byte, and an accessible_ atomic bool. At 4-byte values, nodes are about 30% larger than a skip-list node of expected height close to 1. The overhead shrinks linearly as value size grows — by 64-byte values, it is under 5%.
3. No custom comparator or const_iterator yet. Both are on the roadmap.
The decision rule I actually use:
| Your workload | Pick |
|---|---|
| Reads > 80%, working set > L2 | ConcurrentRBTree |
| Writes > 20% | ConcurrentSkipList |
| Tiny set, extreme thread count, mixed workload | ConcurrentSkipList |
| Range scans matter a lot | ConcurrentRBTree |
| Memory-constrained, tiny values | ConcurrentSkipList |
A note on range scans
One payoff I did not expect: range scans are nearly free.
A classical red-black tree range scan has to do an in-order traversal — explicit stack or parent-pointer walks, cost per edge roughly 3× a simple list next. Here, iterator::operator++ just calls accessibleNext() on the underlying linked list. Cost is the same as iterating a std::list.
If your workload does lower_bound + sequential scan (time-series buckets, log queries, range indexes), this is probably the biggest unspoken win — and it comes directly out of the dual-index design rather than being a separate feature.
API: it’s a drop-in for folly::ConcurrentSkipList
#include <ConcurrentRBTree.h>
using namespace gipsy_danger;
auto tree = ConcurrentRBTree<int>::createInstance();
ConcurrentRBTree<int>::Accessor accessor(tree);
accessor.insert(42);
if (accessor.find(42) != accessor.end()) { /* ... */ }
for (auto it = accessor.lower_bound(10); it != accessor.end(); ++it) { /* ... */ }
accessor.erase(42);
Compile with -std=c++17 -DNDEBUG -I/path/to/include. Nothing else.
The Accessor doubles as an epoch guard for an internal NodeRecycler that is directly modeled on folly::ConcurrentSkipList::NodeRecycler: erased nodes stay alive until the last live Accessor releases its reference. Same weak-consistency guarantees as Folly — readers may see stale data but never corrupted state.
Where to go next
- Code: github.com/Joey-Forever/ConcurrentRBTree. Header-only, MIT-licensed, ~1000 lines of C++17.
- Full benchmark matrix (3 thread counts × 4 working sizes × 16 write probabilities, 12 plots): x86_result/
- Full technical write-up (dual-index correctness sketch, deeper hardware-counter analysis, epoch reclamation details): arXiv preprint coming — link to be added.
- Folly upstream proposal: facebook/folly#2638
If you try it on your workload, I would love to hear about it — especially results from people running large read-heavy caches on ARM or POWER. Those architectures are on my roadmap but I have no hardware access yet.
And if you are from the Folly team: ConcurrentSkipList::NodeRecycler is what the reclamation here is directly modeled on. This work would not exist without it. Thank you.
Questions, bug reports, corrections — file an issue on GitHub.
]]>